
tg-me.com/eshu_coding/284
Last Update:
Палантир. Часть 26. Рефлексия год спустя.
#палантир@eshu_coding
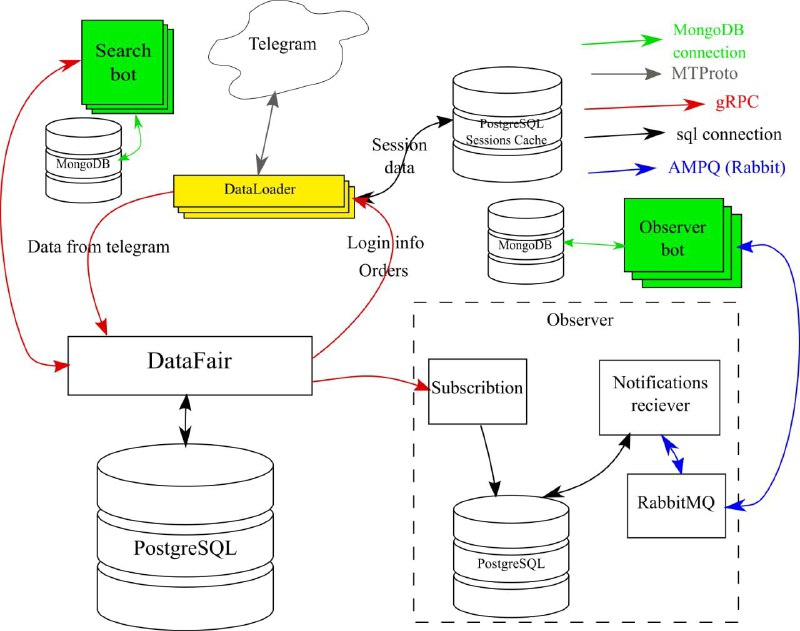
Описание получившейся системы можно посмотреть по ссылке. Намного менее приятной ошибкой было скатывание к монолиту. Центральный сервис (БД на postgresql + надстройка на шарпе) у меня выполнял четыре основные функции:
1. Прием и укладка данных в БД
2. Анализ БД и выдача заданий сборщикам
3. Поисковые кэш и запросы к нему.
4. Анализ потока входящей информации на наличие ключевых слов и выдача оповещений при обнаружении.
Данные попадали в надстройку над БД, проталкивались в базу огромными транзакциями, заодно обновляя служебные таблицы для выдачи заданий сборщикам. Индекс для полнотекстового поиска был построен прямо в основной таблице, поисковые запросы соответственно летели к ней. Триггер, срабатывающий на вставление новых данных, запускал цепочку других триггеров, в которых осуществлялся анализ добавляемого текста. В случае соответствия забитым в базу поисковым паттернам - база отправляла во внешний мир оповещение с помощью функции pg_notify.
В итоге такой подход вылился в жуткую боль как по администрированию, так и по поддержке. В конечном итоге, я вытащил функционал (4) в отдельный сервис, но боль от этого не сильно уменьшилась.
Как на мой нынешний взгляд надо было сделать:
1. Использовать RabbitMQ вместо самопала на gRPC (см прошлый пост)
2. Отработать запись данных в БД. Накрыть тестами функционал.
3. Запустить отдельным сервисом постановку задач сборщикам. Накрыть тестами функционал. Скорее всего, после окончательной отладки этот сервис сольётся с п. 2. Я начал делать их вместе, в итоге так и не смог до конца искоренить дублирование выгружаемых сообщений.
4. Завести отдельную пару сервис + бд для поискового кэша. Сделать как обновление в реальном времени, отведя с помощью RabbitMQ поток данных в сторону + предусмотреть функционал "перелива" данных из основной базы. Теперь я не привязан в PostgreSQL rum индексу на базе дефолтного словаря! И можно экспериментировать с поисковыми движками как душе угодно, не нарушая функциональность основного сервера. Хоть эластик попробовать, хоть сделать прослойку на питоне для умной обработки текста готовыми инструментами.
5. Отвести поток данных для анализа в реальном времени (для выдачи оповещений пользователям) и экспериментировать сколько душе угодно.
P.S. "Отвести поток данных" в случае RabbitMQ значит добавить несколько символов в месте подключения клиентской библиотеки.
P.P.S. Никто не мешает после отладки функционала по отдельности вернуться к монолиту, например для повышения быстродействия. Если закладывать такую возможность на старте - это дело 1-2 дней.
BY Эшу быдлокодит
Share with your friend now:
tg-me.com/eshu_coding/284