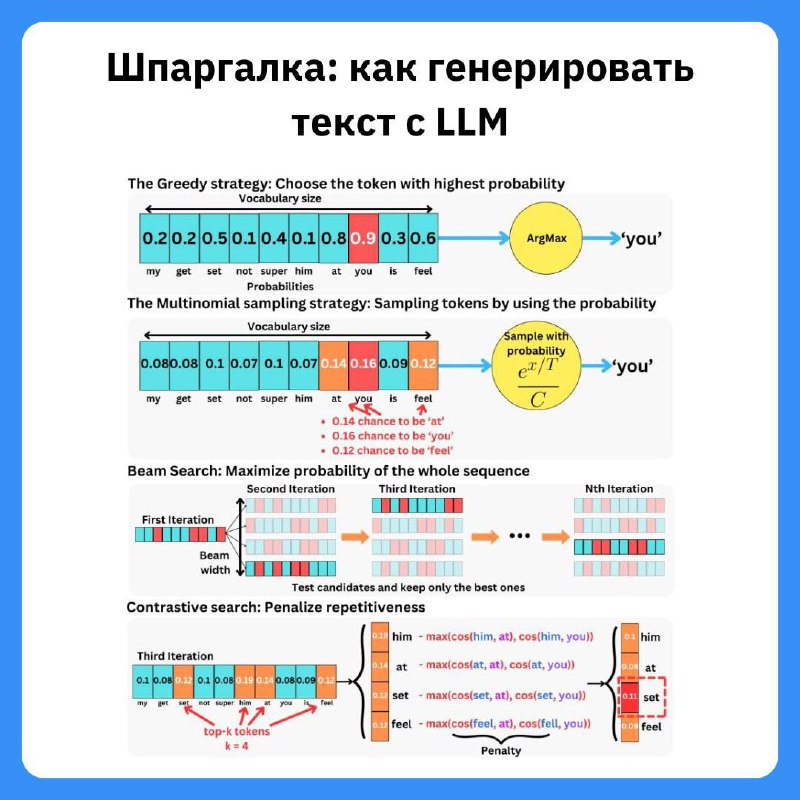
✍️ Шпаргалка: как генерировать текст с LLMГенерация текста — это не просто предсказание следующего токена! LLM оценивает вероятность появления каждого слова, но как выбрать, какие слова вставлять в текст?
Давайте разберём основные методы:
🔵 Жадный поиск (Greedy Search) — выбираем слово с наивысшей вероятностью и продолжаем. Проблема: тексты становятся предсказуемыми и повторяются.
🔵 Случайный отбор (Sampling) — выбираем слова случайно с учётом вероятностей. Регулируется параметром temperature:
🔥 Высокая температура → креативный, но хаотичный текст.
❄️ Низкая температура → логичный, но скучный текст.
🔵 Лучевой поиск (Beam Search) — выбираем k лучших вариантов, продолжаем развивать их и выбираем последовательность с наибольшей вероятностью. Это баланс между качеством и скоростью.
🔵 Контрастный поиск (Contrastive Search) — улучшенный вариант, который оценивает гладкость и разнообразие текста. Слова с высокой вероятностью, но слишком похожие на предыдущие, могут быть наказаны и заменены более разнообразными.
💡 Какой метод лучше?✓ Если нужен фактологичный ответ — лучше beam search
✓Для творческих текстов — sampling
✓ Для баланса между качеством и разнообразием — contrastive search
Библиотека дата-сайентиста #буст