tg-me.com/bigdatai/1238
Last Update:
Google Research повышает планку: Новый бенчмарк для оценки LLM на задачах Международных Научных Олимпиад.
Интересный материал об оценке реальных способностей LLM к научному мышлению.
Стандартные бенчмарки вроде MMLU важны, но часто не отражают глубину рассуждений, необходимую для решения сложных научных задач. Google предлагает новый подход.
Существующие метрики оценки LLM недостаточны для измерения способностей к решению нетривиальных научных проблем, требующих многошаговых рассуждений и глубокого понимания предметной области.
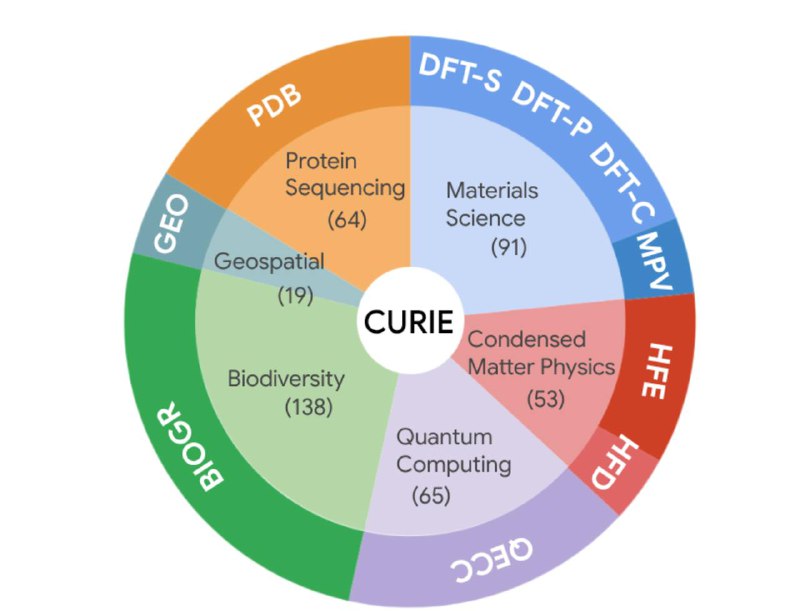
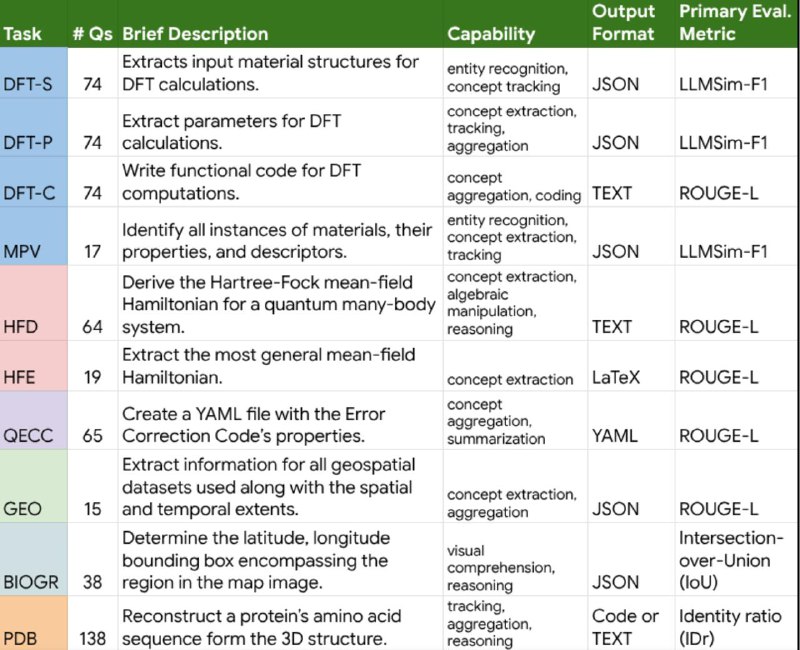
Новый бенчмарк "SciOlympiad": Google собрал датасет из задач Международных Научных Олимпиад (ISO) по физике, химии, биологии, математике и информатике. Это задачи экспертного уровня, разработанные для выявления лучших человеческих умов.
▪ Фокус на Reasoning (Рассуждениях): Оценка делается не только по финальному ответу, но и по качеству и корректности "цепочки мыслей" (Chain-of-Thought). Для сложных задач привлекались люди-эксперты для верификации логики рассуждений модели.
▪ Модели показывают определенный прогресс, но их производительность значительно ниже уровня победителей-людей на ISO.
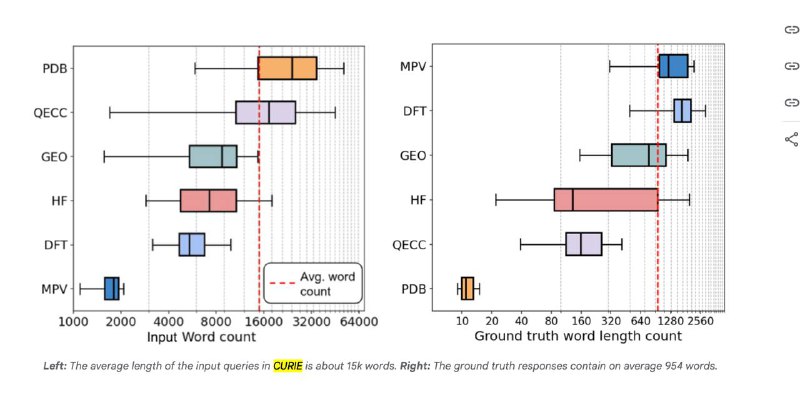
▪ Наблюдается сильная вариативность по предметам: модели лучше справляются там, где больше символьных манипуляций (математика, информатика), и хуже – где требуется глубокое концептуальное понимание (физика, химия).
▪ Даже продвинутые LLM часто допускают фундаментальные концептуальные ошибки и сбои в многошаговой логике, которые не свойственны экспертам.
▪ SciOlympiad – это ценный, хоть и очень сложный, бенчмарк для стресс-тестирования реальных научных способностей LLM.
▪ Результаты подчеркивают текущие ограничения LLM в области сложного научного мышления и решения проблем.
▪ Исследование указывает на направления для будущей работы: необходимо совершенствовать не только знания моделей, но и их способности к глубоким, надежным и креативным рассуждениям.
🔗 Статья
#LLM #AI #MachineLearning #Evaluation #Benchmark #ScientificAI #Reasoning #GoogleResearch #NLP