
DeepScaleR-1.5B-Preview
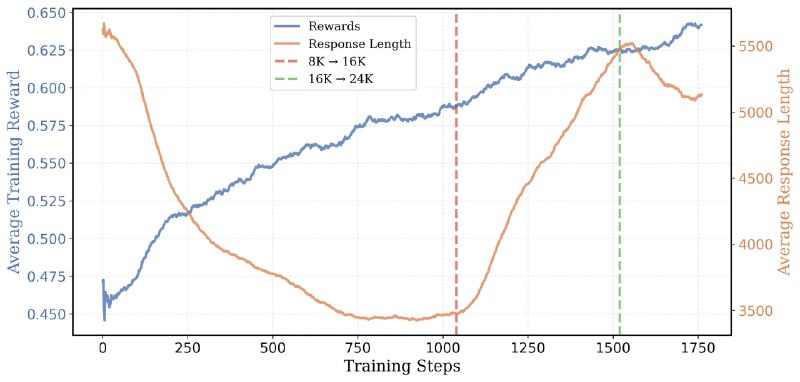
DeepscaleR-1.5b 是在 DeepSeekR1-distilled-Qwen1.5b 上仅使用 3800 A100h(~$4500) 进行 RL 微调的 LLM
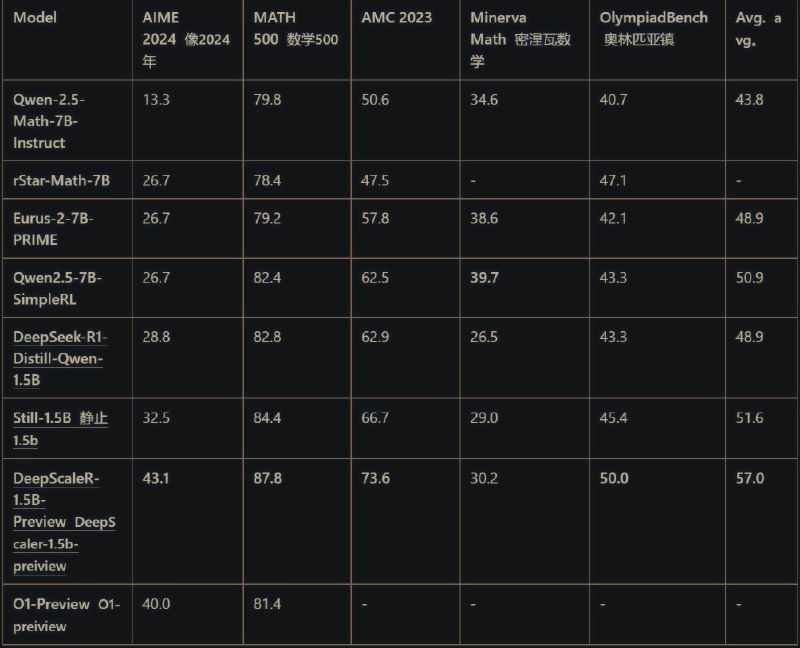
该模型在 AIME 2024 上获得了 43.1%@1 的准确性,较基底(28.8%)提高 14%,在 1.5B 参数下超过了 o1-preview
(Arena Math 中 R1>Gemini 2 Thinking>o1p>Gemini 2 Pro)
Open sourced dataset, code, training logs and models
Github: Github.com/agentica-project/deepscaler
Inference GGUF
#AI
DeepscaleR-1.5b 是在 DeepSeekR1-distilled-Qwen1.5b 上仅使用 3800 A100h(~$4500) 进行 RL 微调的 LLM
该模型在 AIME 2024 上获得了 43.1%@1 的准确性,较基底(28.8%)提高 14%,在 1.5B 参数下超过了 o1-preview
(Arena Math 中 R1>Gemini 2 Thinking>o1p>Gemini 2 Pro)
Open sourced dataset, code, training logs and models
Github: Github.com/agentica-project/deepscaler
Inference GGUF
#AI
tg-me.com/GaryNoHeya/2920
Create:
Last Update:
Last Update:
DeepScaleR-1.5B-Preview
DeepscaleR-1.5b 是在 DeepSeekR1-distilled-Qwen1.5b 上仅使用 3800 A100h(~$4500) 进行 RL 微调的 LLM
该模型在 AIME 2024 上获得了 43.1%@1 的准确性,较基底(28.8%)提高 14%,在 1.5B 参数下超过了 o1-preview
(Arena Math 中 R1>Gemini 2 Thinking>o1p>Gemini 2 Pro)
Open sourced dataset, code, training logs and models
Github: Github.com/agentica-project/deepscaler
Inference GGUF
#AI
DeepscaleR-1.5b 是在 DeepSeekR1-distilled-Qwen1.5b 上仅使用 3800 A100h(~$4500) 进行 RL 微调的 LLM
该模型在 AIME 2024 上获得了 43.1%@1 的准确性,较基底(28.8%)提高 14%,在 1.5B 参数下超过了 o1-preview
(Arena Math 中 R1>Gemini 2 Thinking>o1p>Gemini 2 Pro)
Open sourced dataset, code, training logs and models
Github: Github.com/agentica-project/deepscaler
Inference GGUF
#AI
BY Garyの梦呓

Share with your friend now:
tg-me.com/GaryNoHeya/2920